



”ゼロからつくる”ひらがな認識AI
脱・MNISTということで…。
ひらがな認識AIにチャレンジするぞ!
本シリーズでは、Pythonを使ってひらがな認識AIを作るプロセスを丁寧に解説していきたいと思います。深層学習ライブラリはPytorchを使います。
(脱・MNISTといっても文字認識からは脱していないのは置いといて…)
ひらがな認識タスクでは、MNIST*に比べ分類カテゴリ数は 10→75 に増え(濁音・半濁音・拗音も含む)、さらに
- 「あ」と「お」
- 「ぬ」と「め」
- 「ね」と「れ」と「わ」
- 「は」と「ほ」
- 「り」と「い」
- 「る」と「ろ」
といった見分けづらいものが含まれており、難易度はかなりアップしています。
ある程度までは自力でやってみて、限界を感じたらネットに転がっているテクニックや論文など読んで精度向上を目指したいと思います!
*MNIST : さまざまな画像処理システムの学習に広く使用される手書き数字画像の大規模なデータベース。(Wikipediaから引用)
本シリーズの記事リンクまとめ
本記事の概要
本記事では、
① 学習用のデータを取得し、
② バイナリファイルを変換して学習に使えるデータ型にする
という行程を解説します。
データを取得する
ETL文字データベース
日本語文字認識にうってつけの学習データが「ETL文字データベース」というところにありました。
ETL文字データベース
http://etlcdb.db.aist.go.jp/?lang=ja
1973年~1984年に収集されたデータということで古めのデータですが、手書き文字なので古さは問題にはならないでしょう。
また、研究のために収集されたデータなので結構ちゃんとしたデータっぽいので、これを学習データとして採用しようと思います。
ダウンロード
ETL文字データベースのサイトの「DOWNLOAD」というタブからダウンロードの手続きができます。
「使用条件」を読んで、ページ下部の空欄に必要事項を記入します。「使用目的」の欄には研究用途などと書いておけばいいと思います。
すると自動返信でメールが届き、ダウンロード用のリンクとパスワードが送られてきます。
あとはファイルをダウンロードすればOKです。今回はとりあえずETL8G.zipをダウンロードしておきます。
バイナリファイルを変換する
前節でデータを取得することはできましたが、このままでは学習に使用することはできません。
配布データはバイナリファイルと呼ばれる形式なのですが、これを最終的に普通の数値データに変換したいと思います。
データ変換
次のコードを実行すれば、etlに画像データ(0~15のグレースケール値)とラベル(文字コードの10進表記)が、infoには各画像の付加情報が格納されます。
# ライブラリのインポート
from zipfile import ZipFile
import struct
import numpy as np
from PIL import Image
DATA_PATH = ###--zipファイルがあるディレクトリパス--###
RECORD_SIZE = 8199
etl = []
info = []
with ZipFile(DATA_PATH + "ETL8G.zip") as etl1:
names = [n for n in etl1.namelist() if "_" in n]
for x in names:
with etl1.open(x) as f:
while True:
s = f.read(RECORD_SIZE)
if (s is None) or (len(s) < RECORD_SIZE):
break
r = struct.unpack(">HH8sIBBBBHHHHBB30x8128s11x", s)
img = Image.frombytes("F", (128, 127), r[14], "bit", (4, 0))
img = np.array(img.convert("L")) # 0..15
lbl = r[1]
if lbl in range(int(0x2420), int(0x2474)): # 平仮名のみ
etl.append((img, lbl))
info.append(r[:-1])
# 以下のお二方のコードを参考にさせていただきました。
# kcrtさん https://qiita.com/kcrt/items/a7f0582a91d6599d164d
# 奥村晴彦さん https://okumuralab.org/~okumura/python/etlcdb.htmlバイナリファイルを値に変換するために、Python標モジュールstructのunpack関数を使っています。
第1引数(format):書式文字列
第2引数(buffer):バイナリデータ
重要なのは第1引数の書式文字列ですが、これはデータベースのサイトに公開されているG-Type Data Formatを見る必要があります。
まず1番最初の文字で、データの型を指定します。
| 文字 | バイトオーダ | サイズ | アラインメント |
|---|---|---|---|
@ | native | native | native |
= | native | standard | none |
< | リトルエンディアン | standard | none |
> | ビッグエンディアン | standard | none |
! | ネットワーク (= ビッグエンディアン) | standard | none |
今回のデータはビッグエンディアンなので、最初の文字は”>”となります。
2文字目以降は、書式指定文字を入力していきます。
| フォーマット | C の型 | Python の型 | 標準のサイズ |
|---|---|---|---|
x | パディングバイト | 値なし | |
c | char | 長さ 1 のバイト列 | 1 |
b | signed char | 整数 | 1 |
B | unsigned char | 整数 | 1 |
? | _Bool | 真偽値型(bool) | 1 |
h | short | 整数 | 2 |
H | unsigned short | 整数 | 2 |
i | int | 整数 | 4 |
I | unsigned int | 整数 | 4 |
l | long | 整数 | 4 |
L | unsigned long | 整数 | 4 |
q | long long | 整数 | 8 |
Q | unsigned long long | 整数 | 8 |
n | ssize_t | 整数 | |
N | size_t | 整数 | |
e | 浮動小数点数 | 2 | |
f | float | 浮動小数点数 | 4 |
d | double | 浮動小数点数 | 8 |
s | char[] | bytes | |
p | char[] | bytes | |
P | void* | 整数 |
上の書式指定文字と、下記データフォーマットを照らし合わせながらformatを書いていきます。
| Byte Position | Number of Bytes | Type |
|---|---|---|
| 1-2 | 2 | Integer |
| 3-4 | 2 | Binary |
| 5-12 | 8 | ASCII |
| 13-16 | 4 | Integer |
| 17 | 1 | Integer |
| 18 | 1 | Integer |
| 19 | 1 | Integer |
| 20 | 1 | Integer |
| 21-22 | 2 | Integer |
| 23-24 | 2 | Integer |
| 25-26 | 2 | Integer |
| 27-28 | 2 | Integer |
| 29 | 1 | Integer |
| 30 | 1 | Integer |
| 31-60 | 30 | (undefined) |
| 61-8188 | 8128 | Packed |
| 8189-8199 | 11 | (uncertain) |
したがって、
format = “>HH8sIBBBBHHHHBB30x8128s11x”
となります。
etl, infoの中身を覗いてみると…
print(etl[0])
# (array([[0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0],
# ...,
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0]], dtype=uint8), 9250)print(info[0])
# (1, 9250, b'A.HIRA ', 1, 0, 0, 1, 24, 3552, 0, 8001, 16880, 0, 0)このようになります。一応、可視化してみましょう。
import matplotlib.pyplot as plt
plt.imshow(etl[0][0], cmap="gray_r")
plt.show()
ちゃんとデータが変換できたことがわかります。
ラベルを文字コードから文字へ変換
ラベルは16進数の文字コード(JIS X 0208)を10進表記したものが、etlの中でラベルとして紐づいています。
ラベルをこのまま扱うとして先に進んでも、もちろんいいのですが…。
ラベルが文字になっていた方がこの先の確認作業時にわかりやすいかなと思うので、文字コードを文字に変換したいと思います。
JIS X 0208とUnicode間の変換表が公開されているのでそれを使います(要ダウンロード)。
下のコードでは、変換表を読み込み、JIS X 0208の10進表記のコードを入れると対応する文字を返す関数decoderを定義しています。
import os
ar = []
with open(DATA_PATH + "JIS0208.TXT") as f: # DATA_PATHに変換表を配置
for t_line in f:
if t_line[0] != "#":
sjis, jis, utf16 = os.path.basename(t_line).split("\t")[0:3]
ar.append([jis, utf16])
ar = dict(ar)
def decoder(x):
x = str(hex(x))[2:]
return chr(int(ar["0x"+x.upper()], 16))
# こちらの方のコードを参考にさせていただきました。
# hinomaさん https://qiita.com/hinoma/items/9e96b25eeeee01437c88試しにさっきのelt[0]のラベルをdecoderに入れてみましょう。
print(decoder(etl[0][1]))
# あ無事に「あ」と出力されました。
付加データを整える
これはオマケですが、文字を書いた人の年齢とか職業も紐づいているのでこれもついでに整理してしまいましょう。
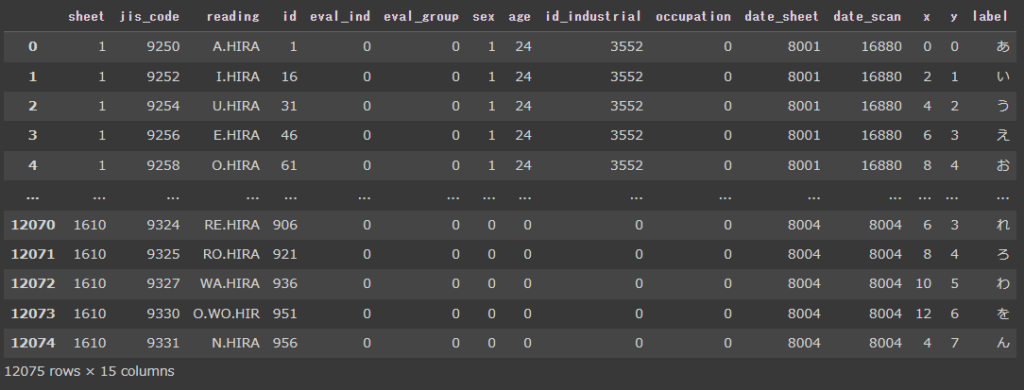
必要な情報はinfoに入っています。これをPandasのDataFrameに入れて見やすくしてみましょうか。
import pandas as pd
col_names = ["sheet","jis_code","reading","id","eval_ind",
"eval_group","sex","age","id_industrial","occupation",
"date_sheet","date_scan","x","y"]
df = pd.DataFrame(info, columns=col_names)
df["reading"] = df["reading"].apply(lambda x: x.decode())
df["label"] = df["jis_code"].apply(decoder) # 文字コードを文字に変換各カラムの意味はETLデータベースのサイトに公開されています。
sheet: Serial Sheet Number (greater than or equal to 1)
jis_code: JIS Kanji Code (JIS X 0208)
reading: JIS Typical Reading ( ex. “AI.MEDER” )
id: Serial Data Number (greater than or equal to 1)
eval_ind: Evaluation of Individual Character Image (>= 0)
eval_group: Evaluation of Character Group (greater than or equal to 0)
sex: Male-Female Code ( 1=male, 2=female ) (JIS X 0303)
age: Age of Writer
id_industrial: Industry Classification Code (JIS X 0403)
occupation: Occupation Classification Code (JIS X 0404)
date_sheet: Sheet Gatherring Date (19)YYMM
date_scan: Scanning Date (19)YYMM
x: Sample Position X on Sheet (greater than or equal to 0)
y: Sample Position Y on Sheet (greater than or equal to 0)
DataFrameは次のような感じになると思います。
データをながめてみよう!
ここまでで、学習に使えるデータになるように様々な処理をしてきました。
最後に変換後のデータを可視化して終わりましょう!
import japanize_matplotlib # 日本語を表示させるのに必要
perm = np.random.permutation(range(len(etl)))
for k in range(24):
plt.subplot(3, 8, k+1)
plt.xticks([])
plt.yticks([])
img, lbl = etl[perm[k]]
plt.imshow(img>=4, cmap="gray_r")
plt.title(decoder(lbl))
plt.show()
# こちらの方のコードをほぼそのままパクりました。
# 奥村晴彦さん https://okumuralab.org/~okumura/python/etlcdb.html


記事への意見・感想はコチラ