


本記事の概要
この記事は「ゼロから作るひらがな認識AI」シリーズの2記事目です。
本記事では、
① Pytorchを使った簡単なCNNモデルを構築し、
② 予測結果を可視化する
という行程を解説します。
本シリーズの記事リンクまとめ
前準備
前回取得したデータを準備する
前回のこちらの記事で取得したデータを使います。

下のコードは前回の記事の再掲です。
from zipfile import ZipFile
import struct
import numpy as np
from PIL import Image
import os
import pandas as pd
DATA_PATH = ###--zipファイルがあるディレクトリパス--###
RECORD_SIZE = 8199
etl = []
info = []
with ZipFile(DATA_PATH + "ETL8G.zip") as etl1:
names = [n for n in etl1.namelist() if "_" in n]
for x in names:
with etl1.open(x) as f:
while True:
s = f.read(RECORD_SIZE)
if (s is None) or (len(s) < RECORD_SIZE):
break
r = struct.unpack(">HH8sIBBBBHHHHBB30x8128s11x", s)
img = Image.frombytes("F", (128, 127), r[14], "bit", (4, 0))
img = np.array(img.convert("L"))
lbl = r[1]
if lbl in range(int(0x2420), int(0x2474)):
etl.append((img, lbl))
info.append(r[:-1])
ar = []
with open(DATA_PATH + "JIS0208.TXT") as f:
for t_line in f:
if t_line[0] != "#":
sjis, jis, utf16 = os.path.basename(t_line).split("\t")[0:3]
ar.append([jis, utf16])
ar = dict(ar)
def decoder(x):
x = str(hex(x))[2:]
return chr(int(ar["0x"+x.upper()], 16))
col_names = ["sheet","jis_code","reading","id","eval_ind",
"eval_group","sex","age","id_industrial","occupation",
"date_sheet","date_scan","x","y"]
df = pd.DataFrame(info, columns=col_names)
df["reading"] = df["reading"].apply(lambda x: x.decode())
df["label"] = df["jis_code"].apply(decoder)Tensor型に変換・データ分割
今回は、このデータを学習に使える形にちょこっと変換していきます。
まずは、必要なライブラリをまとめてインポートしましょう。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split最初にやらねばならないのは、チャネルの追加です。
今の画像データの形を見てみると
print(etl[0][0].shape)
# (127, 128)なので、これは
(高さ, 幅)
という形になっています。
しかし、畳み込み層に画像を入力する際、チャネルの部分がないとうまく動きませんので、新しくチャネルをnp.newaxisで追加します。
画像データはXという変数に入れておくことにします。
# 画像データ
X = np.array([etl[i][0] for i in range(len(etl))], dtype="float32")
# チャネルを追加
X = X[..., np.newaxis]
print(X.shape)
# (12075, 127, 128, 1) --> (データ数, 高さ, 幅, チャネル数)ラベルについてもyという変数に入れておくのですが、その際ラベルには0から始まる整数を割り当てます。
例) ラベルが [“あ”, “い”, “う”, …]なら、[0,1,2,…]とする。
# ラベルのリスト
label_list = df["label"].unique()
# 各ラベルに番号を割り当てる
label_dict = {k:v for v,k in enumerate(label_list)}
print(len(label_list)) # ラベルの種類数
# ラベルデータ
y = np.array([label_dict[decoder(etl[i][1])] for i in range(len(etl))], dtype="int64")
print(y.shape)
# (12075,)次にやるのは、Tensor型への変換です。
PytorchではTensor型でデータを扱うため、事前にデータをTensor型へ変換する必要があります。
変換の仕方は簡単で、numpy配列から変換する場合はtorch.from_numpy()を使えばできます。
# tensor型への変換
X_tensor = torch.from_numpy(X)
y_tensor = torch.from_numpy(y)次は、学習用データと評価用データへの分割です。
これは、皆さんおなじみのtrain_test_splitを使います。
ちなみに、stratifyという引数を指定すると、trainとtestでカテゴリの分布が同じになるようにうまく分割してくれます。
X_train, X_test, y_train, y_test = train_test_split(X_tensor, y_tensor, stratify=y_tensor, test_size=0.3, random_state=42)最後に、DataLoaderへ格納します。
DataLoaderを使うことで、簡単にミニバッチを取り出すことができるようになります。
# Datasetの作成
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
# バッチサイズ(1度に処理する画像の枚数)
num_batch = 200
# DataLoaderの作成
train_dataloader = DataLoader(
train_dataset,
batch_size = num_batch,
drop_last = True, # 端数は捨てる
shuffle = True)
test_dataloader = DataLoader(
test_dataset,
batch_size = num_batch,
drop_last = True,
shuffle = True)ここまでで前準備は完了です!いよいよモデルの構築に入ります。
ネットワークの構築
まずはシンプルなモデルから
まずは試しに全結合層のみからなるニューラルネットワークで学習させてみましょう。
# 全結合層のみからなるネットワーク
class LinearNet(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, 1000)
self.fc2 = nn.Linear(1000, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)かなり単純なモデルですが、これで学習させてみましょう。
# エポック数
num_epochs = 5
# 学習率
learning_rate = 0.001
# 画像の画素数
image_size = 127*128
# GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
# モデル
lr_model = LinearNet(image_size, len(label_list)).to(device)
# 損失関数
criterion = nn.CrossEntropyLoss()
# 最適化手法
optimizer = torch.optim.AdamW(lr_model.parameters(), lr=learning_rate)上のコードのように、
エポック数:5
学習率:0.001
最適化:AdamW
で学習させます。
# 学習
lr_model.train() # モデルを訓練モードにする
for epoch in range(num_epochs):
loss_sum = 0
for inputs, labels in train_dataloader:
# GPUにデータをのせる
inputs = inputs.to(device)
labels = labels.to(device)
# optimizer初期化
optimizer.zero_grad()
# 順伝播
inputs = inputs.view(num_batch, -1) # 1次元化
outputs = lr_model(inputs)
# loss計算
loss = criterion(outputs, labels)
loss_sum += loss
# 逆伝播(勾配の計算)
loss.backward()
# 重み更新
optimizer.step()
# 学習状況を表示
print(f"Epoch: {epoch+1}/{num_epochs}, Loss: {loss_sum.item() / len(train_dataloader)}")
# 評価
lr_model.eval() # モデルを評価モードにする
loss_sum = 0
correct = 0
with torch.no_grad():
for inputs, labels in test_dataloader:
# GPUにデータをのせる
inputs = inputs.to(device)
labels = labels.to(device)
# 順伝播
inputs = inputs.view(num_batch, -1)
outputs = lr_model(inputs)
# lossの計算
loss_sum += criterion(outputs, labels)
# 予測値
pred = outputs.argmax(1)
# 正解数カウント
correct += pred.eq(labels.view_as(pred)).sum().item()
print(f"Loss: {loss_sum.item() / len(test_dataloader)}, Accuracy: {100*correct/len(test_dataset):.2f}% ({correct}/{len(test_dataset)})")結果は次のようになりました。
Epoch: 1/5, Loss: 2.230901082356771
Epoch: 2/5, Loss: 0.5480524698893229
Epoch: 3/5, Loss: 0.1666523842584519
Epoch: 4/5, Loss: 0.05848019463675363
Epoch: 5/5, Loss: 0.026670509860629125
Loss: 1.1761162016126845, Accuracy: 72.51% (2627/3623)
シンプルなモデルの割には頑張ってるかな、という感じもしますが、正解率70%では使い物になりません。
畳み込み層CNNを導入
では、画像分野でおなじみのCNNをネットワークに導入しましょう。
# CNNモデルの定義
class CNN(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.block = nn.Sequential(
nn.Conv2d(1, 12, 3),
nn.ReLU(),
nn.Conv2d(12, 12, 3),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.flat = nn.Flatten()
self.fc_block = nn.Sequential(
nn.Linear(12*61*62, 4096),
nn.ReLU(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, output_size)
)
def forward(self, x):
x = self.block(x)
x = self.flat(x)
x = self.fc_block(x)
return F.log_softmax(x, dim=1)先ほどと同様の設定で学習を進めましょう。
# エポック数
num_epochs = 5
# 学習率
learning_rate = 0.001
# 画像の画素数
image_size = 127*128
# GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
# モデル
model = CNN(image_size, len(label_list)).to(device)
# 損失関数
criterion = nn.CrossEntropyLoss()
# 最適化手法
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# 学習
model.train() # モデルを訓練モードにする
for epoch in range(num_epochs):
loss_sum = 0
for inputs, labels in train_dataloader:
# GPUにデータをのせる
inputs = inputs.to(device)
labels = labels.to(device)
# optimizer初期化
optimizer.zero_grad()
# 順伝播
inputs = inputs.view(num_batch, 1, 127, 128)
outputs = model(inputs)
# loss計算
loss = criterion(outputs, labels)
loss_sum += loss
# 逆伝播
loss.backward()
# 重み更新
optimizer.step()
# 学習状況表示
print(f"Epoch: {epoch+1}/{num_epochs}, Loss: {loss_sum.item() / len(train_dataloader)}")
# 評価
model.eval() # モデルを評価モードにする
loss_sum = 0
correct = 0
with torch.no_grad():
for inputs, labels in test_dataloader:
# GPUにデータをのせる
inputs = inputs.to(device)
labels = labels.to(device)
# 順伝播
inputs = inputs.view(num_batch, 1, 127, 128)
outputs = model(inputs)
# lossの計算
loss_sum += criterion(outputs, labels)
# 予測値
pred = outputs.argmax(1)
# 正解数カウント
correct += pred.eq(labels.view_as(pred)).sum().item()
print(f"Loss: {loss_sum.item() / len(test_dataloader)}, Accuracy: {100*correct/len(test_dataset):.2f}% ({correct}/{len(test_dataset)})")結果は次のようになりました。
Epoch: 1/5, Loss: 2.8194761730375744
Epoch: 2/5, Loss: 0.5884318578810919
Epoch: 3/5, Loss: 0.13183059011186873
Epoch: 4/5, Loss: 0.05284224805377778
Epoch: 5/5, Loss: 0.02262050197238014
Loss: 0.6326134469774034, Accuracy: 84.29% (3054/3623)
全結合層のみのネットワークにくらべて、正解率が10ポイント以上向上しました!
予測結果の可視化
ここまでで、簡単なネットワークを設計して学習させてきました。
最後はこの学習したモデルで予測結果を可視化してみましょう。
# テストデータからランダムに1つ選ぶ
r = np.random.randint(len(X_test))
print(r)
# 正解値
ans = label_list[y_test[r]]
# 画像を表示
plt.imshow(X_test[r,:,:,0].numpy(), cmap="gray_r")
plt.title(ans)
plt.show()
# 学習させたモデルで推論
p = model(X_test[r].view(1,1,127,128).to(device))
p = p.detach().to("cpu").numpy()[0]
p = np.exp(p) # log_softmaxを使っているのでexpをとる
# 出力値をresultにまとめる
result = pd.DataFrame([(char,prob) for char,prob in zip(label_dict.keys(), p)], columns=["ひらがな","確率"])
result.sort_values("確率", inplace=True, ascending=False)
result.reset_index(drop=True, inplace=True)
# 正解判定
print("正解" if result.iloc[0,0]==ans else "不正解")
# 分類確率上位5カテゴリを表示
display(result.head())
# 正解値の分類確率を表示
display(result[result["ひらがな"]==ans])こちらのコードを実行すると…
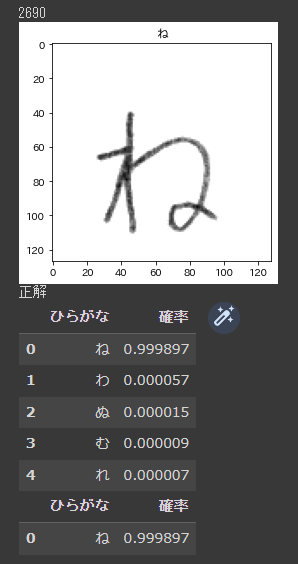
こんな感じに可視化されます。ちゃんと文字認識できているようですね!
しかし、うまく分類できていない文字もまだまだあります。
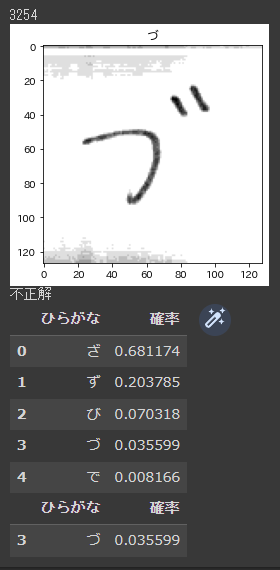
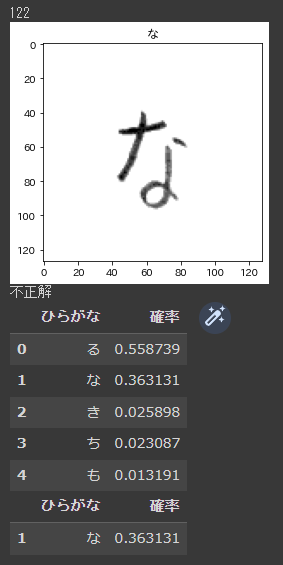
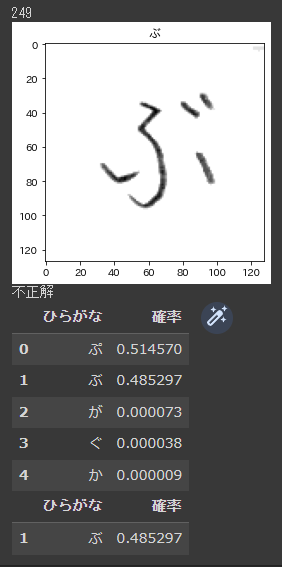
というわけで、次回はネットワークの構造をいろいろ試して精度向上させたいと思います!
目指せ、正解率98%!


記事への意見・感想はコチラ