



Pythonでe-Stat APIからデータをDataFrameとして取り込みたい…。
今回の記事では、
- Pythonで
- 政府統計e-StatのAPIを使って
- PandasのDataFrameにデータを流しこみたい
という人向けに、そのやり方を詳しく解説します!
まずはユーザー登録
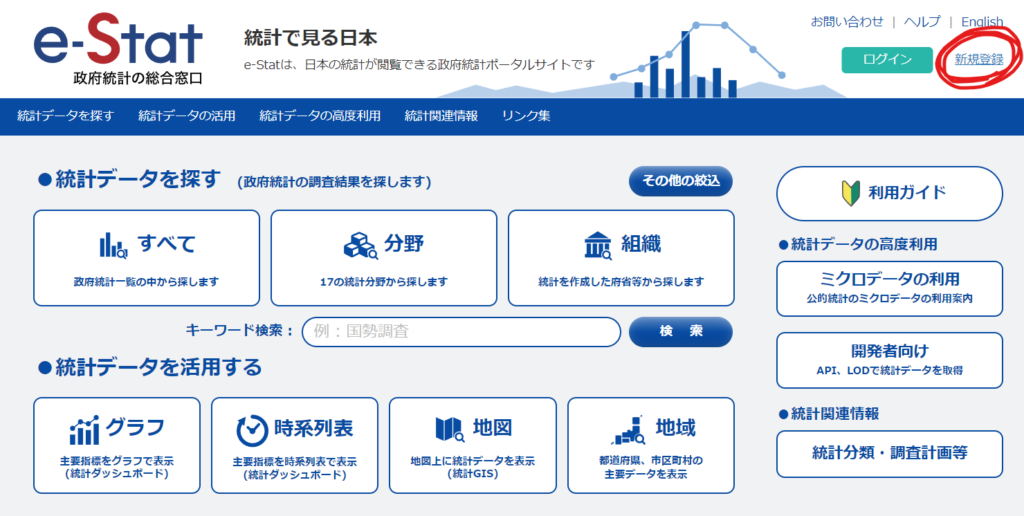
e-StatのWebサイトにアクセスし、右上にある「新規登録」をクリック。
自分のE-mailアドレスを入力して仮登録する。
メールが自動送信されてくるので、メール内のリンクをクリックすると「ユーザー本登録」の画面になる。
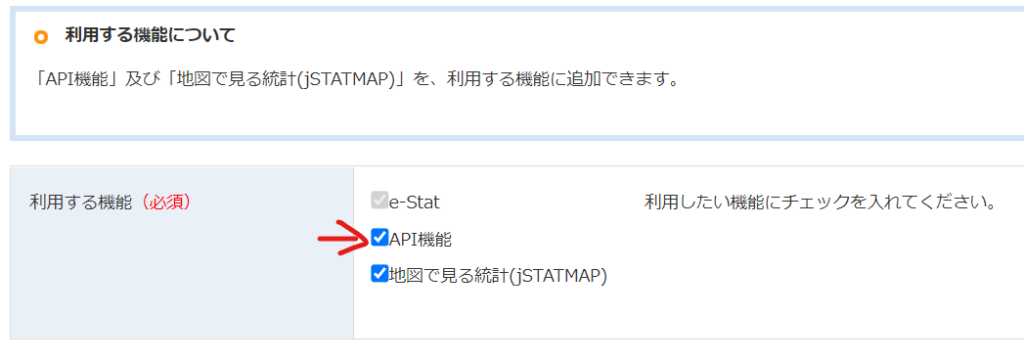
「利用する機能」の項目で「API機能」のところに✓が入っているかを確認してください。
パスワードを登録するか、ソーシャルアカウント連携を行うと本登録が完了します。
アプリケーションIDを取得する
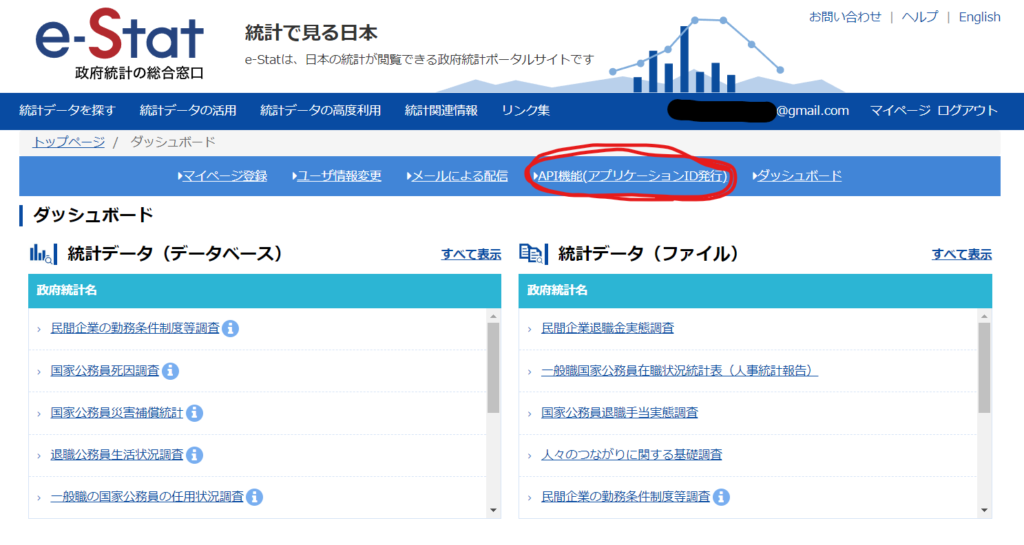
本登録が完了すると、トップページの右上に「マイページ」が現れているはずです。(現れていなければログインしてください)

マイページに行くと「API機能(アプリケーションID発行)」というのがあるのでクリック。各種情報を入力しましょう。
・名称:何でもよい。自分がわかりやすい名前をつけてください。
・URL:ローカル環境でAPIを使う場合は「http://test.localhost/」と入力しておきましょう。
・概要:入力してもしなくてもOKです。
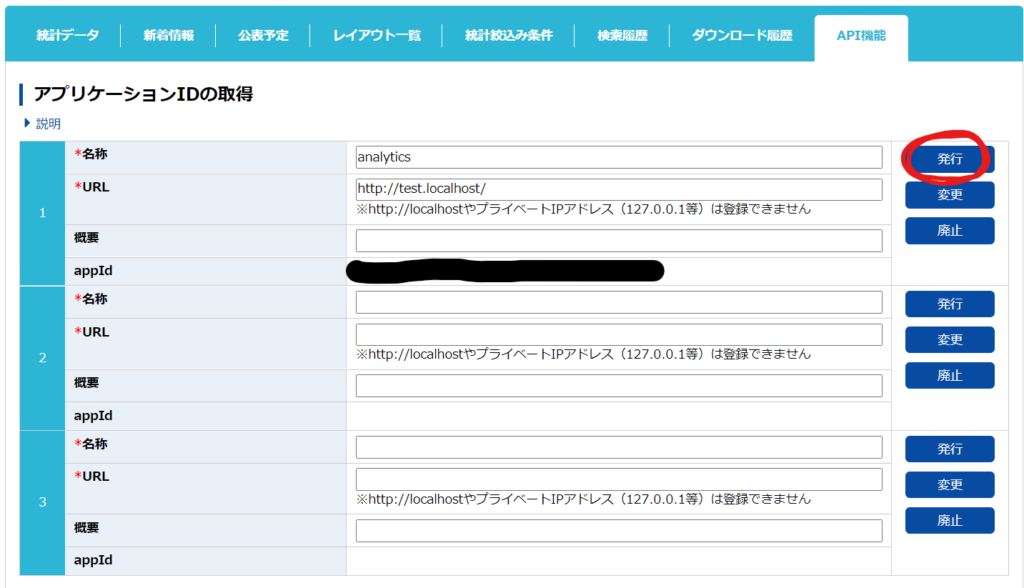
入力出来たら「発行」をクリックします。すると「appId」の項目の場所にアプリケーションIDが表示されます。
APIを使うために必須な情報なので、コピーしておきましょう(マイページにアクセスすればいつでも見られます)。
ここまでで、APIを使うための準備は完了です。
APIを使ってみよう
ではさっそく、実際にAPIを使ってみましょう。
解説で書いたことを、Classで書いてみたものになります。
import pandas as pd
class GetStatsData:
def __init__(self, appId):
self.appId = appId
self.url = None
self.urls = {"xml": None, "json": None, "csv": None}
self.data_types = ["xml", "json", "csv"]
def set_url(self, url):
url_sp = url.split("appId=")
self.url = url_sp[0] + "appId=" + self.appId + url_sp[1]
u_head = self.url[:self.url.find("/app/")] + "/app/"
u_tail = self.url[self.url.find("?appId="):]
self.urls["xml"] = u_head + "getStatsData" + u_tail
self.urls["json"] = u_head + "json/getStatsData" + u_tail
self.urls["csv"] = u_head + "getSimpleStatsData" + u_tail
def get_dataFrame(self, max_col=100):
df = pd.read_csv(self.urls["csv"], names=range(max_col))
idx = df[df[0]=="VALUE"].index[0]
header = df.iloc[idx+1].values
df_val = pd.DataFrame(df[idx+2:].values, columns=header)
df_meta = df[:idx].set_index(0)
df_val = df_val.dropna(axis=1, how="all")
df_meta = df_meta.dropna(axis=1, how="all")
return df_val, df_meta
def get_url(self, dtype):
return self.urls[dtype]
appId = ### アプリケーションID ###
URL = "http://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?appId=&lang=J&statsDataId=0003317642&metaGetFlg=Y&cntGetFlg=N&explanationGetFlg=Y&annotationGetFlg=Y§ionHeaderFlg=1&replaceSpChars=0"
get_df = GetStatsData(appId)
get_df.set_url(URL)
val, meta = get_df.get_dataFrame()ライブラリのインポート
import pandas as pdデータ取得のしくみ
e-Statでは、URLのパラメータをいじることでデータを取得することができます。
URLのパラメータというのは、URLの中の「?」以降(下に太字で示した)の部分を言います。
http://api.e-stat.go.jp/rest/3.0/app/getStatsData?appId=&lang=J&statsDataId=0003283047&metaGetFlg=Y&cntGetFlg=N&explanationGetFlg=Y&annotationGetFlg=Y§ionHeaderFlg=1&replaceSpChars=0
よく見ると、
○○○=△△△△△
という形が「&」を介して繋がっています。
例えば
statsDataId=0003283047
は、統計表のIDを表しています。
他にもたくさんのパラメータを設定できますが、詳細はe-StatのAPI仕様をご覧ください。
URLを取得する方法
パラメータを指定することで、データを取得することができるのですが、一つ一つ設定しているのも面倒です。
なのでe-Statのサイトで直接、目的の統計データを検索して取得してしまいましょう。
例えば、交通事故の発生状況に関するデータを検索したら下のような画面になります。
そして「API」のボタンをクリックすると、次のような画面が出ます。
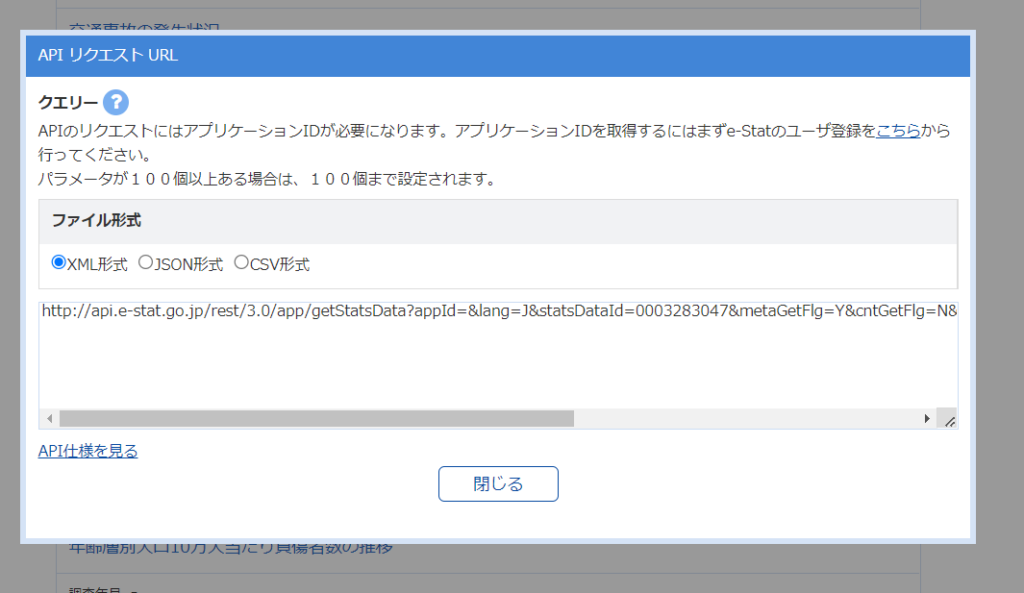
これをコピペしてデータにアクセスできます。
URLにappIDを埋め込もう
先ほど取得したURLをコピペして、そのままアクセスしても認証エラーとなります。
認証するためには、URLのパラメータappIDを指定する必要があります。
手動でコピーしたappIdを、下のように貼り付けてアクセスすることも可能です。
http://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?appId={ここにアプリケーションIDをコピペ}&lang=J&statsDataId=0003317642&……
…しかし、いろいろな統計データにアクセスする場合には面倒になります。
なので、以下のように認証済みURLを生成するプログラムで自動化します。
URL = "http://api.e-stat.go.jp/rest/3.0/app/getStatsData?appId=&lang=J&statsDataId=0003283047&metaGetFlg=Y&cntGetFlg=N&explanationGetFlg=Y&annotationGetFlg=Y§ionHeaderFlg=1&replaceSpChars=0"
appId = ### ここにアプリケーションIDを入力 ###
url_sp = url.split("appId=")
url = url_sp[0] + "appId=" + appId + url_sp[1]
print(url)CSVデータを読み込もう
URLを取得できたら、そこにアクセスしてPandasで読み込めばOK!
…と言いたいところですが、そのままpd.read_csv()として読み込んでも次のようなエラーが出てしまいます。
ParserError: Error tokenizing data. C error: Expected 2 fields in line 10, saw 3
「(CSVの)10行目に2列分のデータがあると思ったけど、3列も見つかっちゃいました!」
と言っているみたいです。どうやら、DataFrameの列数はCSVの1行目で決まるみたいです。
このエラーは、pd.read_csvの引数namesを指定することで解消できます。
# DataFrameの列名を「0,1,2, … ,99」と指定する
df = pd.read_csv(URL, names=range(100))何列あるかはデータによってさまざまなので、上のコードでは大きめに見積もって100列分読み込む設定にしました。
こうして、CSVファイルをDataFrame化することができます。
「データ」と「統計表情報」を分割しよう
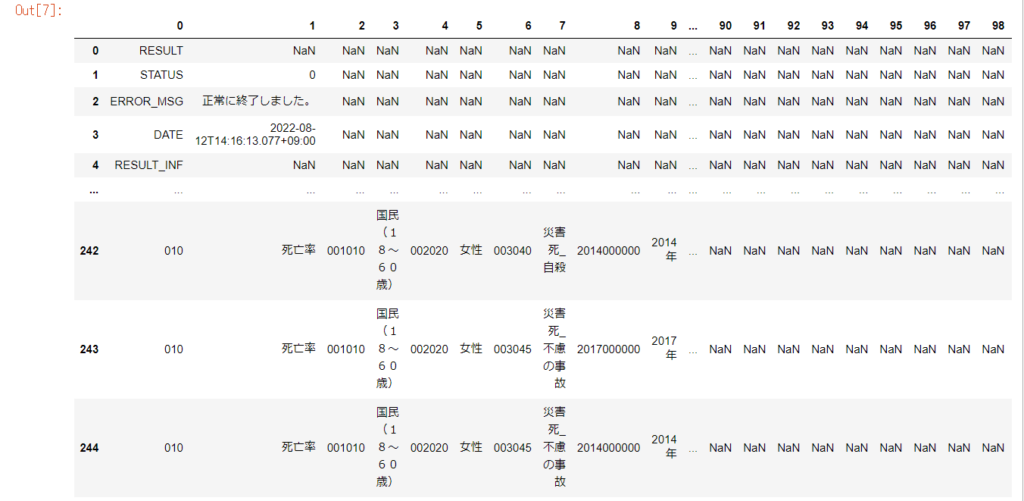
CSVを読み込むことはできましたが、先頭の十数行にはメタデータが記載されており、データ処理するときには邪魔になります。(下図参照)
なので、データが含まれる部分とそうでないメタデータ部分を分割する処理を施す必要があります。
幸い、CSVデータの中には分割する目印となるものがあります。

上図のように、VALUEが含まれる行より上は「メタデータ」で、VALUEより下は「データ」となっています。これを利用して分割します。
idx = df[df[0]=="VALUE"].index[0]
df_meta = pd.DataFrame(df[:idx]).set_index(0)
df_val = pd.DataFrame(df[idx+2:].values, columns=df.iloc[idx+1].values)あとは、余分な部分(NaN)を消してやれば任務完了です!!
df_meta = df_meta.dropna(axis=1, how="all")
df_val = df_val.dropna(axis=1, how="all")

記事への意見・感想はコチラ